by
by 
人資法規需求
人資的基礎基於活生生的人,職場習慣上會用『情理法』的順序在處理事情。但不可否認,有人的地方還是容易遇到爭端,這時候不了解相關法規,對人資個人和公司都會有很大的風險。
人資領域非常廣泛,相關的法規也非常多,招募時可能面對的:就業服務法、性別工作平等法、身心障礙者權益保障法。或是最常見的民法、勞動基準法、勞工保險條例、全民健康保險法…等數十個相關的法律與規範。
對於大型公司來說,相關法律問題可以請教內部法務人員,或是合作的律師事務所,但更多時候是人資需要透過Google 或是自己找資料的方式來確定某些行為是否符合法律規範。
自從像是 ChatGPT這樣的AI工具出現後,也有人會透過ChatGPT來查詢相關法規,但這卻會引起很高的潛在風險 – AI 幻覺 (AI hallucinations)問題。
AI 幻覺問題
Google Cloud 對 AI幻覺的定義是:AI 模型所產生不正確或是誤導的結果。發生的成因有很多可能,訓練資料不足、訓練資料有偏差、模型訓練過程中不正確的參數調整、模型或演算法的先天限制…等。
當AI幻覺問題發生在法律相關的產業中時,往往會造成更大的風險。
紐約時報報導:美國男子 Roberto Mata 控告 Avianca 航空公司的推車讓他膝蓋受傷,他的律師 Steven A. Schwartz 提交的案件摘要中,引用了6項不同航空公司的相關判決。但最終發覺這些案例都是 ChatGPT捏造的,而律師的解釋是,他不知道ChatGPT產生的內容可能是虛假的。
這樣的類似案例陸續在美國、加拿大、英文都陸續產生,AI幻覺問題如果是發生在娛樂上,例如畫出了一隻世界上不存在的可愛動畫角色,其實並不會對生活造成太大問題,但如果AI 幻覺問題是發生在交通、醫療、法律相關的事情上,那就會可能對人造成不可抹滅的影響。
對人資而言,一方面又希望擁抱AI加速效率,但一方面又會害怕 AI幻覺問題帶來的風險,有沒有什麼解決方案呢?
目前普遍所知的解決方案之一是 檢索增強生成(Retrieval Augmented Generation, RAG)。
RAG(檢索增強生成) 怎麼解決AI幻覺問題
為什麼會有AI幻覺
在理解 RAG(檢索增強生成) 怎麼解決 AI 幻覺問題前,先來了解現有ChatGPT的背後運作原理。
ChatGPT 背後的技術基礎是大型語言模型(Large Language Model,LLM),我們可以把它理解成,用大量各領域的文字資料,讓AI模型去學習出其中的通用語言模式。之後我們可以使用這個大型語言模型來做生成內容、回答問題、總結文章、翻譯語言等等工作。
如果要把 LLM 直接應用在人資法律助手上,三個主要原因會導致AI幻覺問題發生:
- 資料不即時:大型語言模型會收集特定時間點之前的資料做訓練,所以就算先前模型在訓練時真的有收錄台灣的相關法律,但大型語言模型不會確認法條是否更新到最新。
- 大型語言模型的生成性質:大型語言模型不單純只會從訓練資料中複製文字出來,他還會創造新的文字內容,所以這很可能會讓他寫出很多不存在的法條或判例。
- 內容的產生基於機率而非正確性:大型語言模型生成的內容是基於計算後認為這是最常出現的形式,而非一定是正確的內容,這也會導致無法確定內容產生的正確性。
一句話說明 RAG(檢索增強生成) 和LLM(大型語言模型)的差異
RAG 對比 LLM 就像是 Open book考試 和 Closed Book考試的差異。
Closed Book考試你需要先把要考的東西記起來,現場不能參考其他資料作答。LLM(大型語言模型)就是這樣,他會一次收集大量資料一次訓練,但訓練之後資料就停止更新了。
而Open Book考試你可以隨時查找資料,綜合判斷後再回答問題,RAG (檢索增強生成)的概念就是一個可以即時查詢正確資料的LLM。
廢話不多說,我們先直接透過 ChatGPT實作讓大家看RAG跟一般LLM的巨大差異。
手把手打造 人資法律 ChatGPT
我先從人資社團中挑選3個大家問的問題來請教 ChatGPT。
- 新同仁入職5個月工作表現不佳,我可以直接解雇嗎?還是需要進行PIP績效改善計畫?需要付資遣費嗎?
- 因為擔心新進女員工未來會請育嬰假,所以先詢問他過往的育嬰假紀錄,請問這樣有違法嗎?
- 請問醫院是否有規定,需要錄用具有就業能力的身心障礙人數?


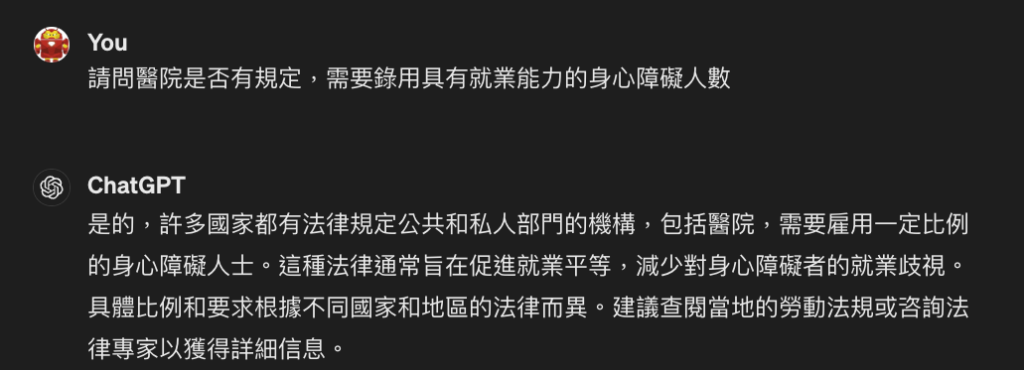
ChatGPT的回答都很模糊籠統,並且沒有依據,雖然看起來都很有道理,但也很難真的用來說服公司接納這樣的意見,同時也會擔心資料的正確性。
接下來我們就來一步步透過 RAG(檢索增強生成) 技術來一步步打造我們的人資法律 ChatGPT。
1. 法規資料整理
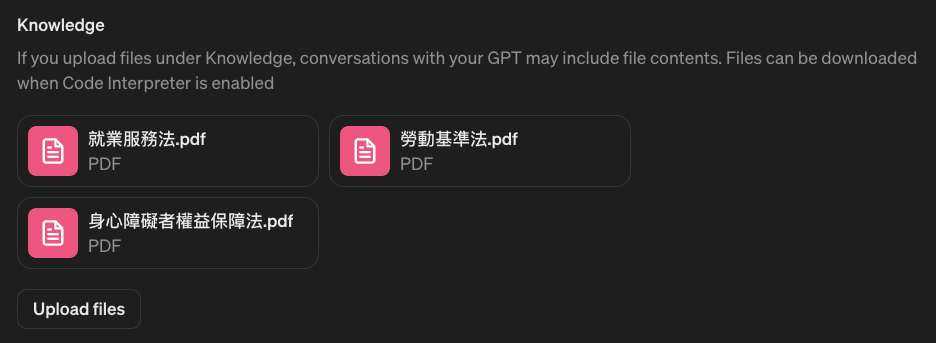
首先我們在台灣全國法規資料庫,搜尋並下載相關法條,因為人資領域的法律非常多,我們這邊就先下載下列法條:性別平等工作法、身心障礙者權益保障法、勞動基準法、就業服務法,下載格式可以透過網頁下載成 pdf 格式。資料準備好就進到下一步。
2. 建立基本 GPTs 並連結法規資料
(接下來操作必須是使用ChatGPT付費版)
開啟ChatGPT 中的 GPTs功能,點擊 Create 按鈕建立自己的 GPT。
進入到GPTs 編輯畫面後把之前下載好的法規pdf 檔案上傳上去。
3. 測試與優化 Prompt
之後切換到 Create 分頁,輸入以下 Prompt:
你是一個台灣人力資源相關法規的助手,所有回答請依據上傳的法律檔案來回答,並且要明確回答出是基於什麼法律的哪一條。如果法條檔案中查不到,就說資料中查不到相關資訊。你只回答人資法律相關問題,如果非法律問題請說你無法回答。
然後透過 Prompt 幫他取名:”台灣人資法律小幫手”。
之後就可以在旁邊的 Preview Tab進行測試了。我們一樣輸入剛剛的三個問題來看結果。



可以看到,回答都有直接帶出明確的法條,並且回頭去查看文件後,也確認引用的法條是正確的。這樣就完成我們的人力資源法律小幫手了。
4. 發佈工具
完成後,我們可以點擊右上方的 “Create”來發佈這個小幫手,看是要只給自己使用、分享給朋友或是要發佈到GPT Store都可以。
以上就是不用寫程式就能做到RAG的方式,再來讓我們往下鑽深一些。
RAG(檢索增強生成) 到底是什麼?
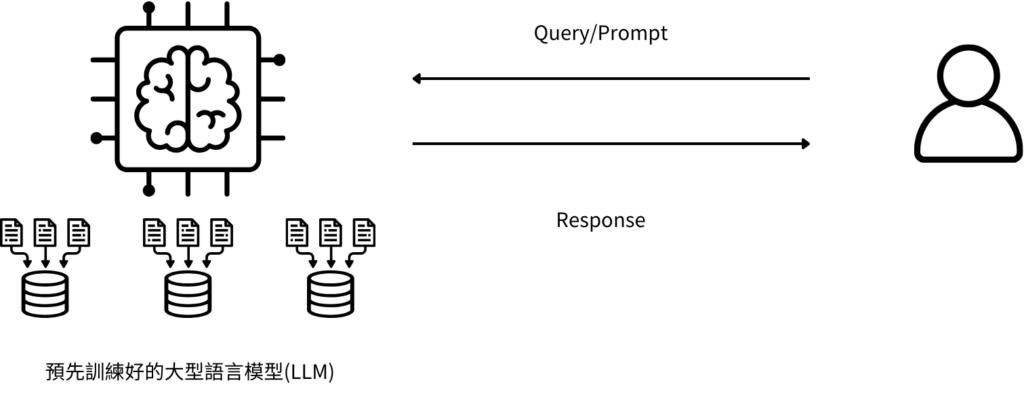
在解釋 RAG(檢索增強生成) 之前,先理解一般大型語言模型的架構,大型語言模型會透過大量不同領域的文本資料做訓練,但一經模型訓練完成後,內建的資料就不再更新了,大型語言模型也不會針對特定領域做優化。
簡單理解 RAG(檢索增強生成) 是透過外部提供大型語言模型特定資料,來加強其回答能力的技術。
當使用者問問題時,問題都會優先拿去特定的資料中做搜尋,之後抓出相關資料後,再混合大型語言模型原有的能力來回答問題,透過這樣的方式增加正確性,也降低 AI幻覺的問題。
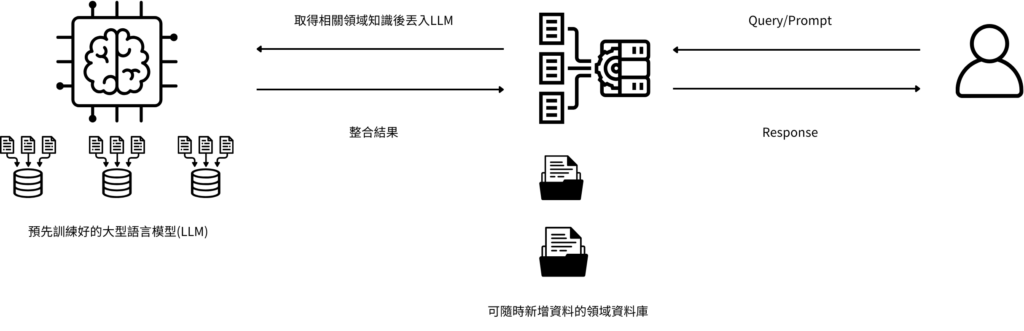
同時這樣的優點就是可以隨時動態新增資料,確保資料都是最新的。
更進階的 RAG (檢索增強生成) 做法
透過 ChatGPT 來做到 RAG(檢索增強生成) 是一種辦法,但還是有許多限制,例如ChatGPT對於上傳檔案的數量和尺寸都有限制,或是對於檔案中資訊的時間性無法加強處理。並且透過Prompt 調整的回答還是會有它的上限,有時候還是多少會出現一些不如預期的回答。
如果已經確定要做更進階的 RAG(檢索增強生成) ,建議可以從 AWS 或是 GCP 這種大廠的解決方案開始嘗試,好處是有較多人已經用過,並且也可以獲得較完整的服務。或是可以從社群很多人使用的 Framework像是: LangChain下去做嘗試,都是相對簡單的開始方式。
結論
RAG(檢索增強生成) 可以降低 大型語言模型的 AI幻覺問題,並且實作的成本比起像是重新訓練模型或是 Fine-tune模型都來得低。所以當今天使用情境對於回答的正確性要求比較高,而不希望回答有太多創意時,可以優先參考 RAG技術。
AI不是萬靈丹,但只要充分理解AI技術的限制和調整辦法,絕對可以讓人資工作事半功倍,我們也在持續研究把AI和RAG技術更好地應用在 HR Tech和自動化上,有興趣的人都歡迎留言跟我們討論你們想把 RAG使用在哪些人資場景上!